
人工知能を用いて遺伝子とその機能の相互関係を見つける手法を開発
ゲノム創薬への応用に向け学外研究機関と共同研究を開始
東京工科大学(東京都八王子市片倉町、学長:軽部征夫)応用生物学部の村上勝彦准教授らの研究チームは、人工知能(AI)を使い、相互に関係する遺伝子や機能をデータベースから自動的に見つける方法を開発しました。10月より、ゲノム創薬などへの応用に向け、学外の研究機関との共同研究を開始しました。
【背景】
生命現象を理解する上で重要な遺伝子がもつ機能の情報は、公共データベースに蓄えられ、世界中の研究者に利用されています。本来、生命現象は相互に繋がっているものですが、遺伝子の機能情報は別々に書かれており、それらの中に特別な関係があるかはこれまで解明されていませんでした。本研究では、こうしたデータベース上の機能情報を「機械学習」させる人工知能技術によって、それらの間に隠れている相互関係を見つけることを目的としました。
【成果】
ヒト遺伝子の機能情報をデータベースから収集し、ある特定の機能を持った遺伝子の多さなどの統計的情報を「非負値行列因子分解」(※1)という方法で総合的に解析しました。その結果、遺伝子や機能情報の間に、書かれていなかった新たな相互関係を見つけることに成功しました。(図1)
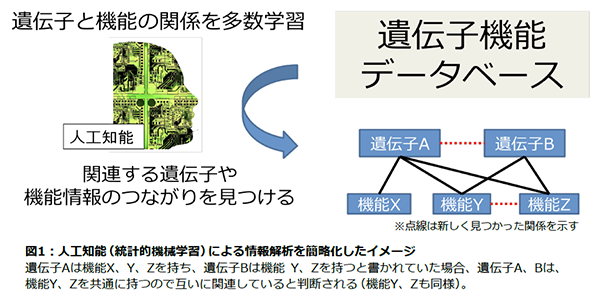
【社会的・学術的なポイント】
本研究により、生命の実験的研究によって蓄積された大量のデータを処理することで、その中に隠れていた関係を取り出せることが明らかになりました。この仕組みを用いることで、AIが遺伝子の相互関係を自動的に探しだし、利用者が次に調べそうなことを先取りして解説するなど、さまざまな情報処理が高度になることが期待されます。
今後、がんの疾患情報といった他のタイプのデータを加えることで、遺伝子同士の新たな結びつきの発見など、がんの分子メカニズムの解明に役立つことが期待されます。また、他の生物種などに対象をひろげていくことで、実験可能な生物の研究が進むことが期待されます。
(※1)非負値行列因子分解:行列形式のデータがあったとき、それを因数分解のように分解し、基本的な構成要素をみつける方法。遺伝子発現量、文書、音声、画像などさまざまなタイプのデータ解析に適用されています。
■東京工科大学応用生物学部 村上勝彦(生命情報)研究室
測定技術の進歩によりDNA配列をはじめバイオデータの大きさは急激に増加しており、これらのデータをうまく生かすためには、コンピューターを使った解析が必須となっています。本研究室では、実験データの解析を簡単・正確に行う計算方法やソフトウエア、アプリの研究開発をはじめ、それらを使いさまざまな生物の細胞のなかにある生命の設計図(DNA配列)の意味付けを行っています。
多くの生物のDNA配列を比較することでその進化を解明する研究や、個人の遺伝情報(ゲノム情報)の違いが薬の効き方にどう影響しているかを予測するため、タンパク質や薬などの分子相互作用の実験データをおさめたデータベース開発、及びそれらから新たなルールや全体像をとりだす方法の研究などを行っています。
[主な研究テーマ]
1.進化の系統や仕組みを解明する研究
2.文献にある知識をデータベースへ効率的に格納する技術の研究
3.DNA変異がタンパク質や化学反応を経て疾患などの表現型へどう影響するかを推論する研究
4.タンパク質や分子の相互作用を予測する技術の研究
5.人工知能をもちいたタンパク質機能など予測方法の研究
【研究内容に関しての報道機関からのお問い合わせ先】
東京工科大学 応用生物学部 准教授 村上勝彦
Tel 042-637-2459(研究室直通)
E-mail murakamikh(at)stf.teu.ac.jp
※(at)はアットマークに置き換えてください。